![]()
Rで非線形回帰分析&ggplot2で描画:対数近似の例(R)
- Part 1:データの整形(tidyr::gathar())
- Part 2:非線形回帰分析(nls()&glm()で対数近似・パラメータ推定)
- Part 3:ggplot2で描画(複数のデータセットを重ね描き)
Part 1:データの整形(tidyr::gathar()&tapply())
2つの何らかの変数間(例えば刺激の長さに対する反応率)に、以下のような関係性があるとします。
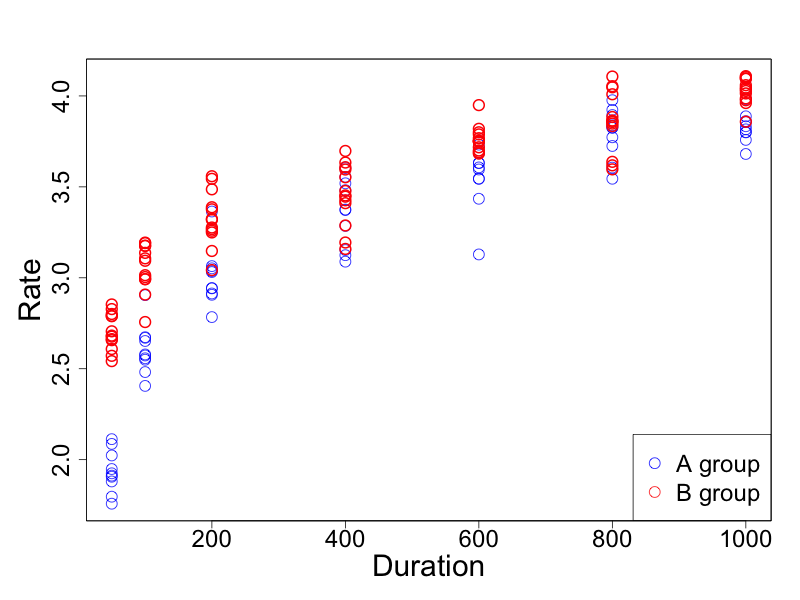
線形的な関係にはありませんが、徐々に値の増加が逓減するようです。
このようなデータに対して、式 y = a* log(x) + bを当てはめ、係数a,bを求めます。
○ 整然データへの変換
もとのデータセット(データフレーム形式:data.frame)を以下のようなものとします。
> dat
group ID d50 d100 d200 d400 d600 d800 d1000
1 Agroup a1 1.880285 2.904563 2.941955 3.603208 3.128457 3.605824 3.800835
2 Agroup a2 1.757871 2.572784 3.064179 3.375248 3.595536 3.724828 3.680834
3 Agroup a3 1.912131 2.669923 3.051985 3.481685 3.732220 3.838531 3.856359
.
.
.
21 Bgroup b11 2.705704 3.014327 3.387839 3.426294 3.788381 4.047547 3.961151
22 Bgroup b12 2.853430 3.175194 3.042429 3.595403 3.752035 3.637675 4.045536
23 Bgroup b13 2.608311 3.176657 3.323680 3.410398 3.767554 4.053566 4.059078
データは条件が被験者ごとに横並びになっています。
列IDより右には、各刺激条件ごとの反応率が、2群それぞれの被験者ごとに横並びになっています。
EXCELのような表ではこのような形がみやすいのですが、このままですと使いづらい(ggplot2で扱えない)ので、ロング形式(整然データ)へと変換を試みます。
ANOVA君/より高度な入力方式
変換は、for文で力技でやる方法もありますが、ここでは"tidyr"を使います。
もとのワイド形式データのID列より右、各条件の反応率をrateという列にまとめてしまい、条件名はdurationという列にまとめてしまいます。
library(tidyr) d <- gather(data = dat, key = duration, value = rate, -group, -ID)
う〜ん、超便利。
引数keyには条件名(値のカテゴリ)、valueには反応率(値そのもの、従属変数)を指定します。
もとの列groupとIDは、手が加えられずに、下へ継ぎ足されていった行数分だけ各値が繰り返されます。
まだこれだと若干使いづらいので、群ごとに行をまとめます。参考
ついでに、各条件も文字列になっているので、数値に変換してしまいます。
duration <- c(50, 100, 200, 400, 600, 800, 1000) d$duration <- rep(duration, each = nrow(dat)) d <- d[order(d$group), ] # group名で昇順(アルファベット順) rownames(d) <- c(1:nrow(d)) # 行番号(インデックス)がバラバラなので、変更。
これで、ローデータを扱いやすい形へ変換できました。
○ 条件ごとの平均値を算出しデータフレームを作成
群ごとにデータを分け、tapply()でdurationごとにrateの平均値を出します。参考
ag <- d[d$group=="Agroup", ] # 列groupが"Agroup"の行を抽出する。data.frameやmatrixは"[ 行 , 列 ]"に対応。
bg <- d[d$group=="Bgroup", ]
agmean <- tapply(ag$rate, ag$duration, mean)
bgmean <- tapply(bg$rate, bg$duration, mean)
d2 <- data.frame(
group = rep(c("Agroup","Bgroup"),each=length(duration)),
duration = rep(duration, 2),
rate = c(agmean, bgmean),
coln = rep(c("col1","col2"),each=length(duration)) #後でggplot2で任意の色を付ける場合
)
これでローデータ、平均値のデータセットがそれぞれできあがりました。
Part 2へ続く。